
Data Science Bootcamp: Linear Regression & Decision Trees Made Simple — with Code Examples


Hey data friends! 👩🏼💻Ashley here. In this blog post I will cover the following topics:
I. Introduction — A brief overview of three foundational data science techniques geared towards beginners.
II. Linear Regression — Overview of Linear Regression, how & why it’s used, & a code example.
III. Decision Trees — Definition of Decision Trees, how & why it’s used, & a code example.
IV: Conclusion — Recap of the three techniques covered & twelve individually curated suggestions for further reading & resources for beginners in Data Science!
I. Introduction
So….

Data science is a field that combines statistics, math, computer science, domain knowledge, & more to extract insights & knowledge from data. It is an ever-growing & multidisciplinary field that is used in a wide range of industries, including finance, healthcare, marketing, & technology.
Data scientists use a variety of techniques to analyze & interpret data, including linear regression, decision trees, & clustering, which I will focus on in this blog post. Understanding these techniques is essential for effectively solving data science problems & making informed decisions based on the results.
So without further adieu, here are three popular (& beginner friendly!) techniques used in Data Science include: Linear Regression, Decision Trees, & Clustering:
✔️Linear regression is a technique used to model the relationship between a dependent variable & one or more independent variables. It is commonly used to make predictions & understand the impact of different factors on a given outcome. During my first few semesters, my foundational data science courses focused heavily on linear regression & logistic regression and understanding the mathematical concepts behind them!
✔️Decision trees are a technique used to make predictions based on feature values. They are useful for classification & regression tasks & can be used to understand the decision-making process behind a given outcome.
Of course these techniques can get increasingly more complex depending on various use cases & specific data, but these three techniques are a great starting point for you to build a foundation your data science career!
Now, let’s learn all about Linear Regression!
II. Linear regression
What is Linear Regression?
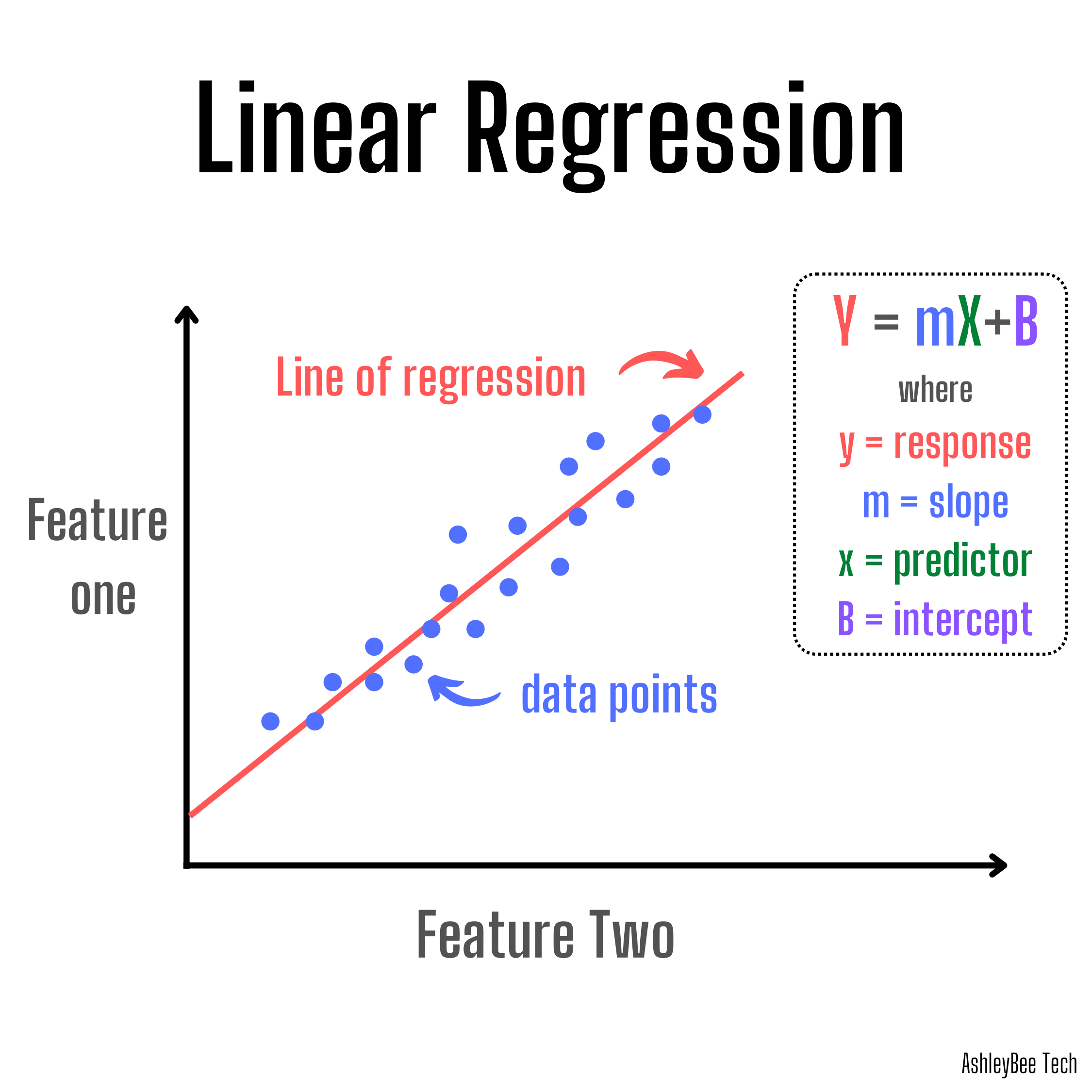
Linear Regression is a statistical method used to model the linear relationship between a dependent variable & one or more independent variables. It is used to make predictions about the dependent variable based on the values of the independent variables.
Tips for implementation a linear regression model:
✏️Choose an appropriate model
It is important to choose a linear regression model that is appropriate for your specific dataset and the questions you may want to answer. This may involve considering the types of variables involved (continuous, binary, categorical), the presence of multicollinearity (correlation between independent variables), & the distribution of the data.
✏️Assess model performance
It is important to assess the performance of the linear regression model to ensure that it is making accurate predictions. This can be done by evaluating the model’s coefficients, residuals, & goodness-of-fit measures such as R-squared and adjusted R-squared. The Bias-Variance Tradeoff is an incredibly important concept to learn about when you are evaluating your model performance.
✏️Check assumptions
Linear regression assumes that the relationship between the variables is linear, the errors are normally distributed, & the variance of the errors is constant. It is important to check for the presence of these assumptions to ensure that the model is valid.
✏️Consider feature selection
Depending on the number of independent variables & the complexity of the data, it may be beneficial to select a subset of the variables to include in the model. This can be done through techniques such as forward selection, backward elimination, or stepwise regression.
Code Example — Linear Regression
# Import your Libraries
import pandas as pd
from sklearn.linear_model
import LinearRegression
from sklearn.model_selection
import train_test_split
# Load the datadf = pd.read_csv('ashleys_dataset.csv')
# Split the data into feature matrix (X) & target vector (y)
X = df.drop('target', axis=1)y = df['target']
# Split the data into training & test setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=88)
# Create a linear regression modelmodel = LinearRegression()
# Train the model on the training data
model.fit(X_train, y_train)
# Make predictions on the test data
predictions = model.predict(X_test)
# Evaluate the performance of the Linear Regression Model using mean squared
# and r-squared
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse:.2f}')
print(f'R2 Score: {r2:.2f}')
Are you enjoying my blog? Help support me by sharing and subscribing!
III. Decision Trees
What are are Decision Trees?
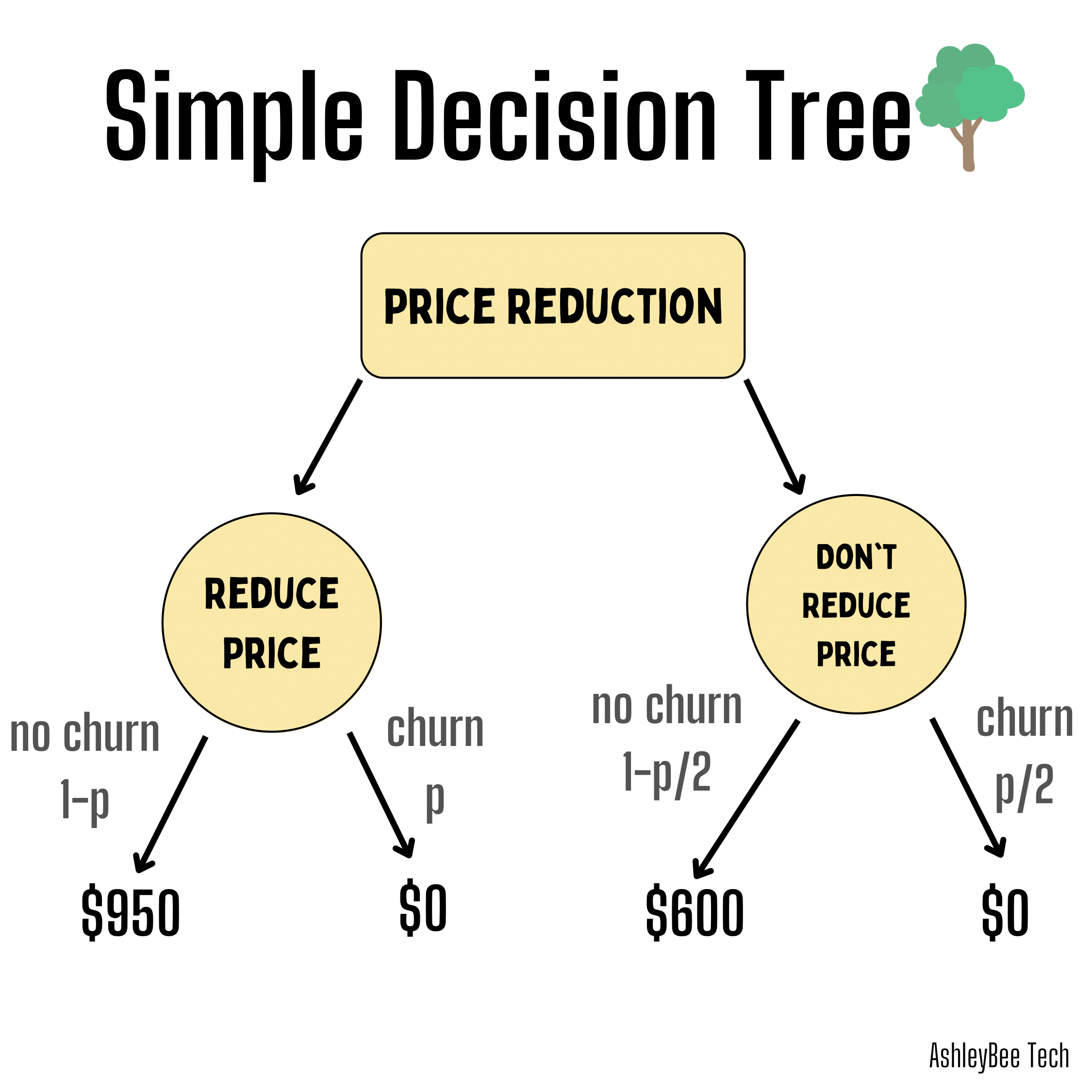
A decision tree is a machine learning algorithm used to make predictions based on a set of features. It is a flowchart-like tree structure (such as the one above), where an internal node represents a feature, & each leaf node represents a class label.
Decision trees are commonly used in classification tasks, where the goal is to predict a categorical label based on a set of features. They can also be used for regression tasks, where the goal is to predict a continuous outcome.
Tips for implementing a decision tree:
✏️Choose an appropriate model
It is important to choose a decision tree model that is appropriate for the data & the research question. This may involve considering the types of variables involved (continuous, binary, categorical), the size of the data, & the desired level of interpretability.
✏️Assess model performance
To ensure that our decision tree model is making accurate predictions, it’s important to look at the performance and decide our “goodness” of the model. This can be done through techniques such as cross-validation, confusion matrix analysis, & evaluation metrics such as accuracy, precision, & recall.
✏️Tune hyper-parameters
Decision tree models have a number of hyper-parameters that can be adjusted to improve performance. These may include the maximum tree depth, minimum number of samples per leaf, & criterion for selecting features.
✏️Consider ensemble methods
Ensemble methods, such as random forests & gradient boosting, can improve the performance of decision trees by aggregating the predictions of multiple decision trees. Although they can be a bit more complex to understand, these methods can be more robust & less prone to overfitting than a single decision tree and are important models to consider as you get further into your data science journey.
Code Example — Simple Decision Tree Classifier
# Import your libraries
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# Load the data
df = pd.read_csv('ashleys_dataset.csv')
# Split the data into feature matrix (X) and target vector (y)
X = df.drop('target_variable', axis=1)
y = df['target_variable']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=88)
# Create a decision tree classifier
clf = DecisionTreeClassifier()
# Train the model using the training data
clf.fit(X_train, y_train)
# Make predictions on the test data
predictions = clf.predict(X_test)
# Evaluate the model's performance
accuracy = clf.score(X_test, y_test)
print(f'Accuracy: {accuracy:.2f}')IV. Conclusion
Here is a short recap for you of the techniques I covered in this blog post:
🔹Linear regression is a statistical method used to model the linear relationship between a dependent variable & one or more independent variables. It is often used to predict the value of the dependent variable based on the values of the independent variables. In data science, linear regression can be used to predict a numerical value, such as the price of a house based on its size & location.
🔹Decision trees are a type of machine learning algorithm that can be used to classify data into different categories. They work by making decisions based on feature values & creating a tree-like model of decisions. In data science, decision trees can be used for classification tasks, such as identifying whether a customer will churn based on their past behavior.
As always with these techniques, it is incredibly important to get out there and try them out on real data! This is the best way to learn & grow as a data scientist. Understand the concepts, and go apply them. Happy analyzing!🙂
— Ashley

Further Readings & Resources
Here are my carefully curated suggestions for further reading & resources for learning more about all things Data Science!
I want to first recommend following Renee Teate. She was my inspiration to get into Data Science while I was a flight attendant and her content is incredibly helpful. https://twitter.com/BecomingDataSci Although I did not mention SQL in this blog post, she has wonderful book “SQL for Data Scientists: A Beginner’s Guide for Building Datasets for Analysis” that I highly recommend checking out!
Resources for Data Science:
“Data Science from Scratch” by Joel Grus is a good introduction to data science concepts and techniques.
“Doing Data Science” by Cathy O’Neil and Rachel Schutt is a more advanced book that covers a wide range of data science topics.
Coursera has a great course, “The Data Scientists Toolbox”, taught by Johns Hopkins University professors, is a comprehensive and free online course that covers many of the key concepts and tools of data science with a focus on R programming.
Another great Coursera course (Python focused), “Applied Data Science with Python Specialization” taught by University of Michigan professors. “This skills-based specialization is intended for learners who have a basic python or programming background, and want to apply statistical, machine learning, information visualization, text analysis, and social network analysis techniques through popular python toolkits.
Resources for Linear Regression:
“An Introduction to Statistical Learning” by James, Witten, Hastie, and Tibshirani is a great book that covers linear regression as well as other machine learning techniques.
Khan Academy has a series of videos on linear regression that I found helpful to learn the mathematical concepts behind this method.
I love this video by StatQuest, Linear Regression, Clearly Explained! which goes over the concept of Linear Regression and shows examples step-by-step.
Resources for Decision Trees:
“Decision Trees for Business Intelligence and Data Mining” by Larose is a comprehensive book on Decision Trees with practical applications in the Business field using SAS Enterprise Miner.
“Decision Trees and Random Forests: A Visual Introduction For Beginners” by Chris Smith. “This book is a visual introduction for beginners that unpacks the fundamentals of decision trees and random forests. If you want to dig into the basics with a visual twist plus create your own algorithms in Python, this book is for you.”
As always, feedback is greatly appreciated! I am constantly working to improve my content & research & I would love to collaborate with others in the field. Please feel free to reach out to me at ashleyha@berkeley.edu or connect on LinkedIn https://www.linkedin.com/in/ashleyeastman/ or Twitter at https://twitter.com/ashleybeeTech